

作者:连昱 | 2025年2月22日
当硅谷巨头深陷千亿美元参数竞赛时,杭州幻方量化旗下的AI实验室以557万美元训练成本,在全球AI领域点燃效率革命。这场突破引发两极评价,诚如美国AI博主、MedARC创始人亚伯拉罕所言:
“部分人工智能专家,特别是OpenAI阵营,意图低估DeepSeek的价值。与此同时,另一些专家或“自封专家”则对其反应过激,不吝溢美之词……但毋庸置疑,DeepSeek 值得认可,R1模型令人印象深刻。” [1]
喧嚣与赞誉,误读与曲解,DeepSeek的创新价值究竟何在?其崛起背后,真实的逻辑又是什么?我们通过技术、成本、地缘、生态四个方面,解构这场技术平权运动的真实逻辑。
1. 技术神话的祛魅:工程优化,非理论革命
关于DeepSeek的技术成就,业界存在两种截然不同的声音:一类将其技术突破奉为“颠覆性革命”,另一类则贬斥为对海外模型的拙劣模仿,甚至揣测其进步源于对OpenAI模型的“蒸馏”。DeepSeek的崛起常被解读为“颠覆性创新”,实则是一次对既有技术范式的系统性工程优化。更精准地定义,DeepSeek的突破是一场直击产业痛点的工程范式跃迁,为AI推理开辟了一条“少即是多”的崭新路径。
架构瘦身,效能倍增:
DeepSeek运用GRPO(群体相对策略优化)算法,精妙地剔除传统强化学习中结构冗余的Critic模型,化繁为简,将复杂算法转化为可高效落地的工程方案。想象教AI下棋的过程原本需要两个教练:一个负责下棋(Actor,如下图Policy Model),一个负责评分(Critic,如下图Value Model+GAE计算优势函数)。[2]
GRPO算法就像去掉了评分教练,让棋手通过观察自己的胜负直接学习。这就像把航天飞机复杂的推进系统,改造成家用汽车的引擎——虽然功率变小了,但日常使用反而更高效。此举虽未在深度学习理论层面实现突破,却显著地提升了训练效率。
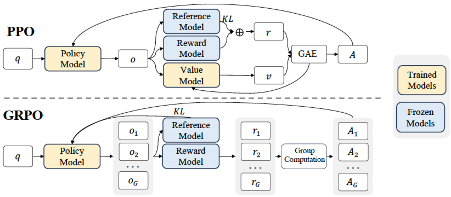
图表 1:DeepSeek的GRPO算法
硬件适配,精益求精:
DeepSeek巧妙地运用PTX编程,深度优化H800芯片的互联效率,实现了硬件级深度优化,提高了推理速度。就像在寸土寸金的市中心,建筑师通过巧妙设计让30平公寓住出40平的感觉。PTX编程就是通过改写“芯片语言说明书”,让H800显卡的显存使用效率提升30%。然而,PTX本质上仍隶属于CUDA生态系统(见图表2)[3],并未从根本上摆脱对英伟达技术的依赖。而从另一方面来看,这种优化方案也不是因为芯片受限的被动选择,而是为了提升芯片适配、提高通信互联效率做的主动优化。[4]
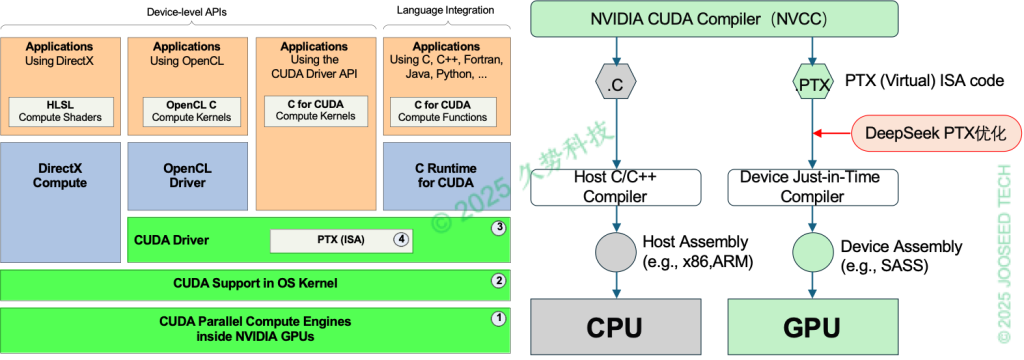
图表 2:英伟达CUDA架构与DeepSeek PTX优化示意
数据策略,量质并举:
DeepSeek创新性地融合“Zero模式”的算法自主进化与“R1模式”的少量人工标注,巧妙地平衡了模型能力与可解释性。Zero模式展示了强大的推理能力,并能够自主发展出意想不到且强大的推理行为,平均响应长度随训练步数增长120%(见图表3)。[5] R1模式在此基础上引入四阶段精调的关键干预:
- 冷启动:用5000条人工标注的长思维链(Long-CoT)数据引导;
- 指令融合:加入语言一致性奖励,解决中英文混杂问题;
- 数据蒸馏:生成80万条优质推理数据,使5B小模型达到Llama 70B 90%的推理能力;
- 安全校准:引入无害性奖励模型,将危险回答率降低至3%。
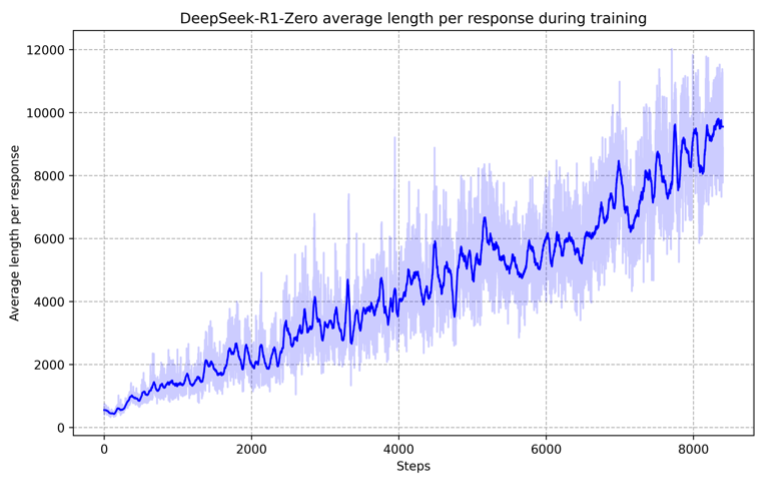
图表 3:DeepSeek-R1-Zero平均回复长度随训练迭代步数的关系曲线
这如同让AI既拥有学霸的题海战术(Zero模式),又获得名师的重点突破指导(R1模式),在数学基准测试中准确率提升达33%。这种策略如同用5%的人工标注数据撬动95%的自动化训练效能,使API成本降至OpenAI o1的1/10。但如同再聪明的学生也需要标准教材,模型冷启动阶段仍需数千条人工标注数据,且合成数据的近亲繁殖风险仍未完全解决。当前方案在数据利用效率上取得突破,但要彻底摆脱对优质数据的依赖,仍需攻克自主数据净化等关键技术难关。
DeepSeek这三个技术本质都在做减法:GRPO减模型复杂度,PTX减资源消耗,数据双轨制减人工干预。DeepSeek的突破,本质上是工程智慧打破技术垄断与算力霸权,使AI技术真正回归服务本质。
2. 成本神话的虚实边界:进击的算法与杰文斯悖论
DeepSeek训练成本低至557万美元的“成本神话”,无疑具有爆炸性的传播力,瞬间引爆全球AI界的狂欢与质疑。然而SemiAnalysis的研究表明 [6],若计入16亿美元服务器采购与9.44亿美元运营成本,实际投入远超表面数字。当然,相较于OpenAI的巨额投入,DeepSeek的成本控制依然堪称卓越。这场成本神话的狂欢背后,潜藏着技术博弈与产业变局的深层逻辑:模型成本的冰山法则、效率与幻觉的算法博弈、算力需求的杰文斯悖论。
模型成本的冰山法则:
DeepSeek的技术报告[7] 明确指出,完整训练流程(包含预训练、上下文扩展及后训练环节),DeepSeek-V3总计耗用278.8万H800 GPU时。相较Meta Llama 3 405B模型的3930万H100 GPU时投入,DeepSeek 以671B的参数量训练仅消耗其1/14的成本,堪称巨大的节约。但这只是覆盖了GPU算力消耗的显性训练成本,背后还有硬件采购、数据清洗、研发团队薪资等一系列隐性成本。若将总拥有成本(TCO,见图表4)纳入考量,实际总支出将远超25亿美元。而DeepSeek今天取得的成果,离不开他们在LLM持续迭代的努力,更离不开幻方时期就开始的AI研发投入。

图表 4:DeepSeek-V3的TCO示意图
效率与幻觉的算法博弈:
DeepSeek的算法工程优化虽未突破理论边界,却通过MoE架构与FP8混合精度将算效比提升至OpenAI同类模型的1/10。[8] DeepSeek采用的动态稀疏专家系统(MoE)堪称“算力节流阀”,仅激活20%参数(约370亿)完成推理,较传统架构降低70%能耗。但这种“选择性清醒”需付出沉重代价——测试显示其幻觉率高达14.3%,是GLM-4模型的11倍。典型案例包括虚构《数据安全法》第87条、篡改国际象棋规则(声称“小兵可斜吃皇后”),甚至在简单数学比较中出现致命错误。2月18日,DeepSeek公布了原生稀疏注意力(Native Sparse Attention, NSA)机制,在维持模型核心能力的前提下,显著提升长文本场景的运算效率,将带来三大价值:
-
- 看得更远:如直接处理整本《三体》小说(约40万字)或整个软件项目代码,这对法律合同审查、多步骤代码生成等场景至关重要。
- 算得更快:64k长度的文本处理速度提升11倍,相当于把原本需要1小时的推理缩短到5分钟,手机也能运行复杂AI任务。
- 学得更省:训练成本降低80%,让更多企业能用得起大模型技术,就像从“超级计算机专属”变成了“家用电脑也能玩”。
DeepSeek是用软件定义硬件的“极致实践”,这种技术取舍的本质是将算力瓶颈转化为系统工程挑战:通过算法创新压缩显性计算成本,但需承受隐性系统工程复杂度指数级增长(如硬件定制化率提升至68%)。
算力需求的杰文斯悖论:
尽管DeepSeek引发英伟达单日市值蒸发5888亿美元,但头部玩家仍在疯狂加注:OpenAI将GPT-5研发预算增至940亿美元,以确保领先;微软计划投资 800 亿美元建设数据中心;xAI携20万块H100集群发布Grok3。当美国科技巨头将AI塑造成 “百亿美元门票” 的昂贵 “神坛” 时,DeepSeek 却另辟蹊径,打开一条通往AGI的新路径,也激发起更多企业自建和应用模型的热潮。这再次印证了杰文斯悖论——训练效率提升反而刺激算力需求的爆发。据IDC预测[9] ,中国AI算力市场规模将以30.6%的复合增长率在2028年达到552亿美元;而中国智算服务市场将保持57.3%的高速(复合)增长,其中智算集成服务和生成式AI基础设施(GenAI IaaS)成为增长的主导力量,2028年规模占比超过90%。
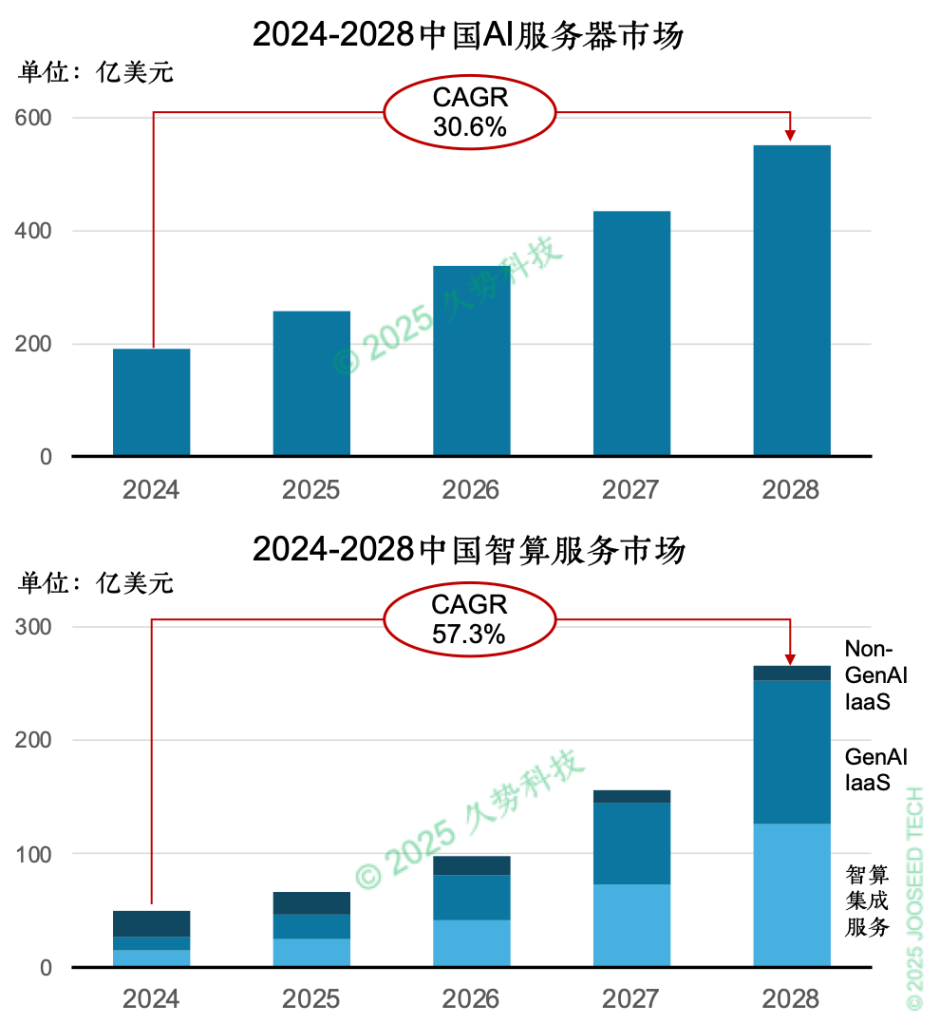
图表 5:中国AI服务器与智算服务市场规模
DeepSeek通过算法与架构创新,在保证模型性能的同时,显著降低了训练与推理成本。DeepSeek“成本神话”的背后,是一场深刻的价值重塑,是对现有行业规则的颠覆性叩问,预示着AI发展进入“价值重塑”的新阶段:未来的竞争,将不再仅仅是算力的堆砌,更是算法创新、工程优化与人本价值的深度融合。
3.地缘博弈之外:技术平权的全球叙事
2025年1月31日起,英伟达、AWS、微软、英特尔、AMD等五大科技巨头相继宣布上架或整合DeepSeek模型,这一事件标志着中国AI技术的全球影响力显著提升。Hugging Face联合创始人德朗格(Clément Delangue)在X上宣布,DeepSeek-R1上线首月下载量突破1000万,成为全球开发者社区的最受欢迎的大模型。然而,将其简单归因为“中国技术胜利”的叙事存在片面性——云服务商的商业逻辑、开源协议的生态效应、地缘政治风险的交织,共同构成了技术平权运动的复杂图景。
云巨头的逐利本性:
全球云服务商对DeepSeek的集成本质上是商业生态的必然选择。以AWS Bedrock为例,其平台已支持超过170个模型,涵盖从文本生成到代码补全的全场景需求,DeepSeek的加入进一步丰富了其AI“工具箱”。这种策略背后是明确的商业考量:模型多样性直接关联客户留存率。这种“技术达尔文主义”下,DeepSeek的价值在于其话题热度与开源属性——据Sensor Tower统计,其关键词搜索量在集成公告发布后激增320%。国内科技公司也在春节后迅速完成部署,华为云于大年初四首发昇腾云服务适配,腾讯云次日推出3分钟极速部署方案,阿里云、百度智能云等均在其后上线全尺寸模型(图表6)。
图表 6:国内外主要科技企业、云服务商上线 DeepSeek时间线
开源协议的双刃剑效应:
DeepSeek被视为开源AI模型挑战闭源技术的垄断地位的一次重大突破,这将促进全球协作、创新和可及性,尤其对发展中国家有益。DeepSeek采用MIT开源协议,客观上推动了AI技术的普惠化进程。开发者可自由调用模型参数,单卡即可模拟集群训练策略,显著降低创新门槛。这一策略也反向促进硬件自主化:通过华为昇腾CANN软件栈优化,DeepSeek-R1在昇腾910B芯片上的推理速度与英伟达H800持平,前者的FP16算力超越英伟达A100 20%,证明了“软件开源+硬件自主”协同创新的可行性。[10] 但开源协议并未改变硬件生态的既有格局,英伟达CUDA仍主导AI训练基础设施,即便中国厂商通过框架优化降低20%成本,其硬件架构依赖短期内难以突破。
合规风险与地缘政治的复杂性:
尽管开源策略在一定程度上降低了政治风险,但DeepSeek遭遇的仿冒域名攻击事件,清晰地揭示了地缘博弈的复杂性与严峻性 ——攻击流量中,高达60%源自美国本土。自1月下旬起,DeepSeek App在全球多个国家和地区遭遇“禁用风波”,包括美国、加拿大、印度、意大利、澳大利亚和韩国。据多方报道,美国 NASA和海军、加拿大联邦政府、意大利隐私监管机构、澳大利亚政府、南韩个人信息保护委员会等均对 DeepSeek App实施限制。但需强调,被限制的仅为DeepSeek App,而其开源软件(如 DeepSeek-V3、R1)继续被科技巨头积极采用,二者性质迥异,不可混淆。这种“应用封禁与技术吸纳并存”的现象,反映了地缘博弈的新形态:终端市场准入限制与底层技术生态控制的双轨策略。
DeepSeek的全球叙事不仅是技术突破,更是开源AI民主化的催化剂,其未来将塑造更具包容性的AI生态,但需平衡商业利益、AI伦理与地缘政治风险。
这场由DeepSeek引发的技术平权运动不仅有望成为算力霸权的破壁者,更是人性化创新的播种机——从复旦的AI大模型助力视障人群“听见世界”,到尼日利亚用DeepSeek-R1构建豪萨语农业咨询聊天机器人[11] ,技术民主化正让AI回归服务人类的本质。正如图灵奖得主杨立昆(Yann LeCun)所说,DeepSeek的崛起并非是“中国战胜了美国,而是开源战胜了闭源”。在这场文明跃迁中,真正的胜利不属于某个国家或企业,而属于每个用技术创造善意的普通人——因为最伟大的创新,永远诞生于对人类尊严的坚守。
参考资料:
- 1 Tanishq AI Blog. (2024, December 20). Debunking DeepSeek Delusions. https://www.tanishq.ai/blog/posts/deepseek-delusions.html
- 2 Guo, S., Xu, G., Zhang, H., Zhao, H., Lu, Y., Lin, W., … & Tang, J. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Large Language Models. arXiv preprint arXiv:2402.03300. https://arxiv.org/pdf/2402.03300
- 3 NVIDIA. (n.d.). CUDA Architecture Overview. NVIDIA Corporation. https://developer.download.nvidia.com/compute/cuda/docs/CUDA_Architecture_Overview.pdf
- 4 电子工程专辑. (2025, February 21). 关于DeepSeek:五大误解与真相解读. https://www.eet-china.com/mp/a380645.html
- 5 Team, D., An, Y., Zheng, G., Liu, X., Zhang, Z., Xu, G., … & Tang, J. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv preprint arXiv:2501.12948. https://arxiv.org/pdf/2501.12948
- 6 Research, S. A. (2025, January 31). DeepSeek Debates: Chinese Leadership On Cost, True Training Cost, Closed Model Margin Impacts. SemiAnalysis. https://semianalysis.com/2025/01/31/deepseek-debates/
- 7 DeepSeek Team. (2024). DeepSeek-V3 Technical Report. arXiv preprint arXiv:2412.19437. https://arxiv.org/pdf/2412.19437
- 8 Fisher Daddy. (2025, February 19). DeepSeek-R1 的训练过程是怎样的?• Epoch AI. Fisher Daddy’s Blog. https://fisherdaddy.com/posts/what-went-into-training-deepseek-r1-by-epochai/
- 9 OFWEEK. (2025, February 21). DeepSeek狂潮下,九张图表详解智算市场走向. OFWEEK人工智能网. https://m.ofweek.com/ai/2025-02/ART-201700-8110-30657172.html
- 10 腾讯新闻. (2025, February 19). 从DeepSeek适配潮看中国芯突围:生态反击!. 腾讯网. https://news.qq.com/rain/a/20250219A01P9Z00
- 11 Rathod, R. (2025, January). Is DeepSeek best open source model Which Enhances AI Reasoning and Accessibility? Medium. https://medium.com/@rajveer.rathod1301/is-deepseek-best-open-source-model-which-enhances-ai-reasoning-and-accessibility-32a95226feb9